May
23
On Using Text Analysis Tools and Web Pages
May 23, 2012 | Leave a Comment
First, a little bit of an introduction. The easy part of any technical project is figuring out “how to do it.” Sometimes students in the New Media Lab come to me to figure out the “how,” and I am always glad to help. But my job isn’t simply to present the “how,” but to complicate* the “how” to help understand the potential ramifications of the technical decision. To do this, first I listen a bit to the description, the goals, the intentions, and then I try to help show how that tool sees this project to completion. This involves a deep understanding of the technology but also the research methods and the content at work.
This holistic understanding of web and strategy isn’t new. Private business and web entrepreneurs now place a high value on this kind of expertise. Around the mid 00’s, many top start-ups and established web companies began hiring UX (user experience) and UI (user interface) experts to redesign their websites and experiences. I don’t think its a coincidence that this was around the same time that the Ipad, the death of flash for website navigation, large text, the web 2.0 “actionable” look [you’ll know it when you see it] and other much ballyhooed easier-to-use web interfaces began popping up**.
{kind=link}
{kind=link}
Anyway, back to the post at hand: How can a complicated look at text analysis tools create a better (and more statistically valid) analysis of the web?
Text Analysis tools started innocently enough as a great way for scholars to analyze word frequencies in entire works of literature at a simple glance.

Wordle is a common mainstream example of a text analysis tool in action.
But what is key is to remember the medium for which these tools were built: corpuses. Books and literature follow a common design trope: title page, acknowledgments, some Library of Congress cataloging information and then the actual text itself. The proportion of ancillary material in a book is small in comparison to the text itself. Maybe 3-4 pages [200-300 words]: 200-300 pages [100,000 words]. Also, often times the ancillary data is not contextual to the book. The name of the publisher, the dedication, etc rarely are in the same tone and world as the book as itself. So although this prefacing information is easy to remove when analyzing a text. If you left it in, the words are not frequent enough in the introduction to significantly*** alter the results.
But the Web is a whole different beast.
Let’s say hypothetically that we wanted to a textual analysis of blogs in the digital humanities.
The first option that comes to mind is to use a tool such as a “website scraper.” These tools go into a webpage, follow all the links on a webpage to basically spider an entire webpage as if it were Google or some other search engine. It then creates an HTML backup of that entire site. A couple of the more common ones are Site Sucker [Mac OS only] an HTTrack website copier [Platform agnostic].
Point the tool to a blog of your choosing, and BAM! Instant backup of everything. So what’s the problem?
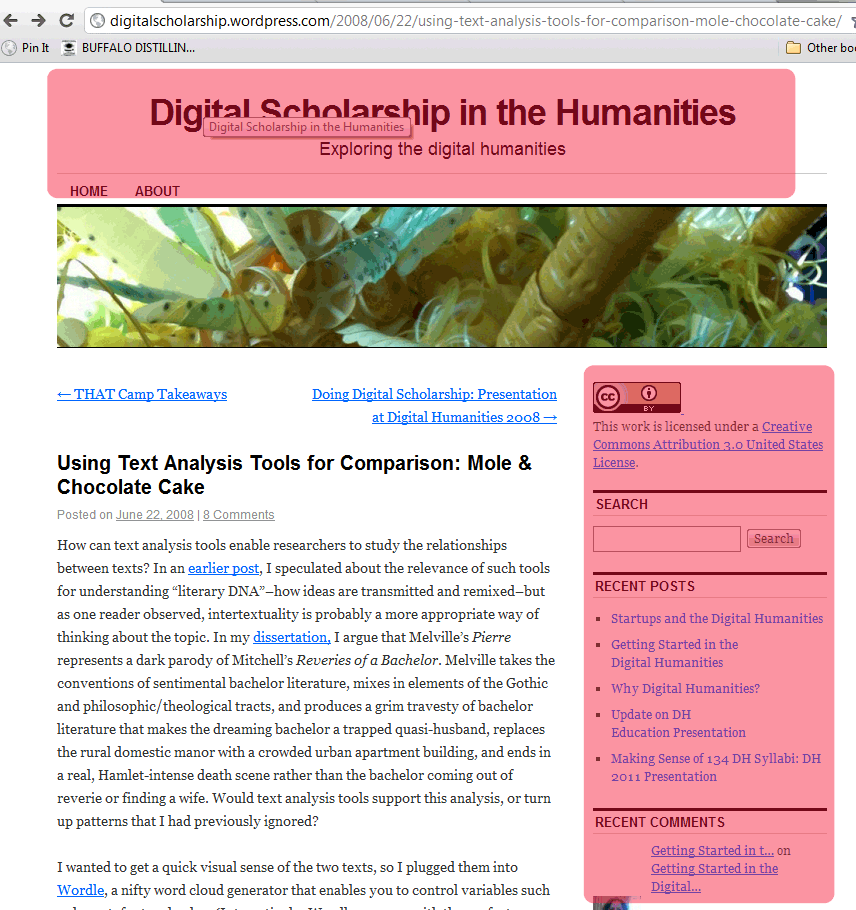
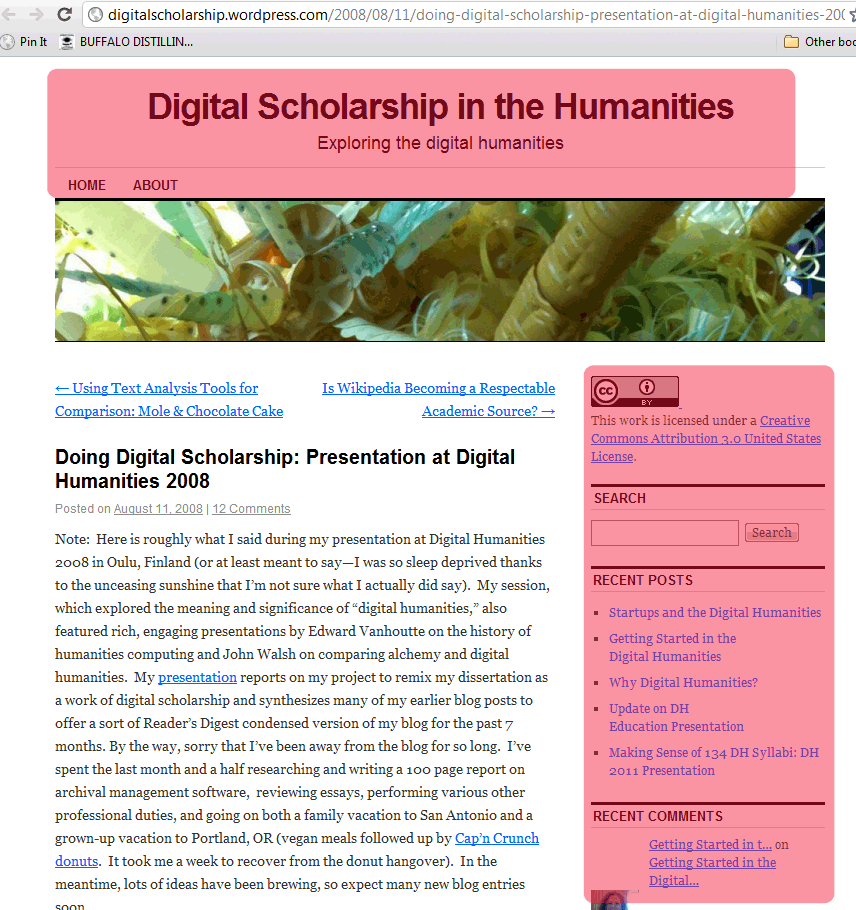
Notice that these are two separate screen shots from the same blog. If we had used Site Sucker, we would have had each of these as an individual file on our computer. Now say that we wanted to see how many times the word EDUCATION appears within our corpus. We’re studying digital humanities, pedagogy and the like and we’re really interested in how blogs on Digital Humanities talk about education.
How many times does the word EDUCATION appear across these two web pages? 10
How man times does the word EDUCATION appear in the actual body of the blog post that is unique to each page ? Only 1.
A detour, and an explanation
Every web page across all major blogging platforms is assembled from a database from a combination of components. You have your “title”, the description of the group that create the website, the list of the most recent titles, and most dangerous of all, you have the blue box in the lower right hand corner. This is the box that seals your fate: the random content from outside sources box.
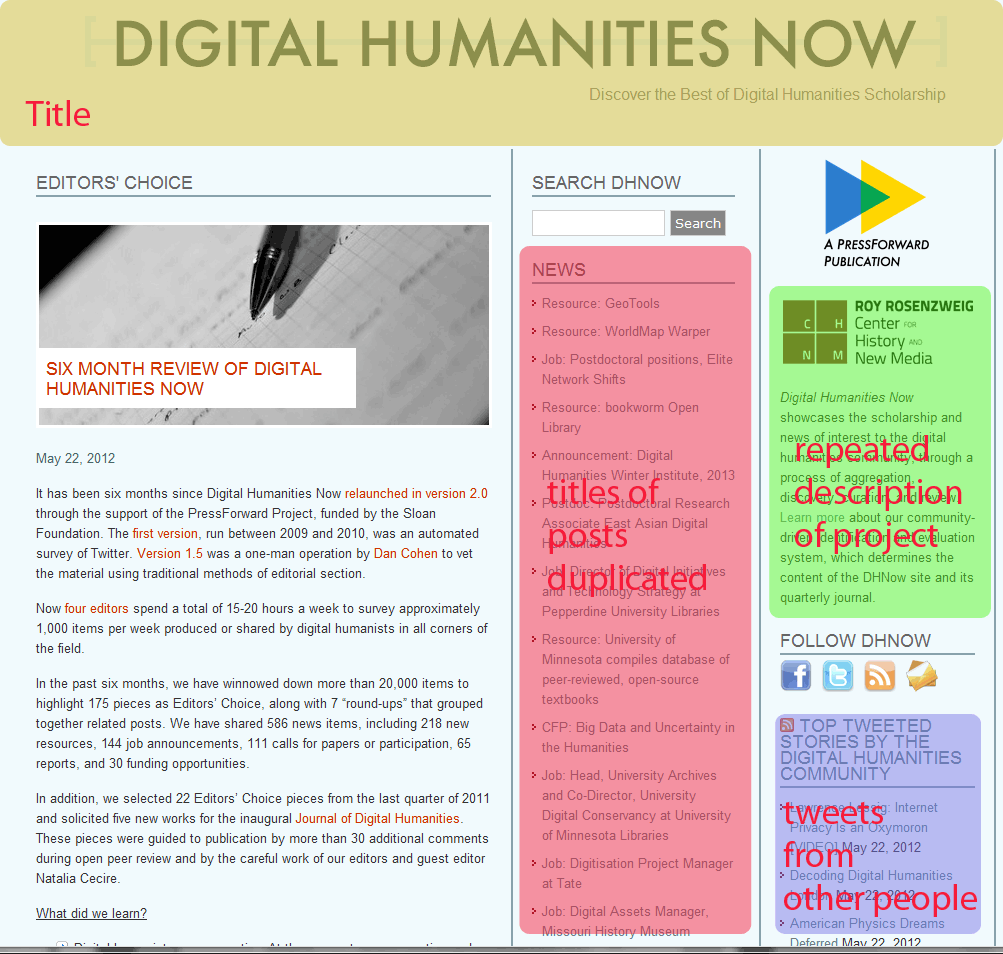
This is the content that can change randomly and often times does not necessarily represent in a 1:1 fashion the topic of the blog. If you want to do a search or textual analysis, with some effort you could probably narrow your vocabulary**** to only use terms that do not appear in the titles, project description, category list, tag clouds, and other more predictable fields. (For a small number of corpuses, or a class project which has no further aspirations such as being published in a peer-reviewed journal, this might give you results which are acceptable).

Google’s Contextual Ad Words pose another huge obstacle to the scholar wishing to use websites for text analysis. They are the most insidious, as Google is using the same text that you’re analyzing to generate advertisements. And these advertisements can be unpredictable, vary from page to page, and often [due to Google’s particularly astute algorithms] going to have words in it which may be very similar to reason a scholar might choose to investigate a specific blog. Interested in how many posts on TechCrunch today talk about App development? The answer is 0, but the advertisements buried on the right hand column will give an artificial positive finding.
So what’s a Scholar to do?
As is my habit, I tend to present a few options. Let’s start with the simple and least technically complex:
If You are Dealing with a small body of text and have a high tolerance for tedious tasks.
You can simply copy and paste the text you wish to analyze into a plain text document. Copy only the entries, the headlines, the tags [if you want them]. This is the low-tech way that will give you the text you need with none of the ancillary information.

If You are Dealing with a fairly large body of texts AND you do not have access to the admin/backend of the blogs

This icon indicates the presence of an RSS feed
This is one place where for most blogs you can make use of the RSS feed to make the job easier. Look for the “RSS” icon on a blog, or search for the words “RSS”, “Atom”, “Subscribe,” or “Feedburner.” Without getting into the differences in each of these technologies, what they have in common is that they will give you a text only print out of the content of the blog you are looking at.
This is not always a fool proof method. Some blogs do not show their entire content in the RSS feed; they often invite you to click more so that they get the ad revenue or website unique visits they need. Others actually have ads in their RSS feeds. These area couple of things you should look out for, but as a general rule I would expect that somewhere upwards of 90% of blogs do not have these things, and accessing an RSS feed is the best way to get only the titles, text, and images from a blog entry.
Screenshot of an RSS Page viewed in Google Reader
From here, it is a cut and paste operation once again, but with all of the entries printed one above the other, it is much easier to do a large number of entries all at once. No clicking from page to page, nor keeping track of where you’ve been [and haven’t]
If you are unfamiliar with how to use RSS, there are plenty of good guides online. It is fairly simple and in most cases you probably already use a program with RSS reading capabilities without realizing it.
If You are Dealing with a fairly large body of texts AND you DO have [or can get!] access to the admin/backend of the blogs
This is by far the most preferred solution, since most blogs allow the easy export of just the textual content. Major platforms such as Blogger, WordPress, and MovableType all support this, as do some less common blogging platforms such as Livejournal or OpenDiary for example. I’m only going to cover a couple to show you how it benefits you in getting clean text to perform textual analysis on, but suffice to say that this is possible on each platform
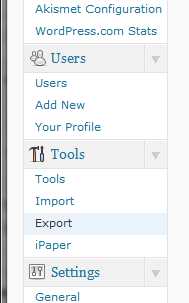 On WordPress
On WordPress
Log into your admin panel.
Go to Tools –>
Click on Export
It now will ask you to choose “what to export.” This is the power of the export feature. You can for example analyze posts and pages separately. You can pick posts only by a category. Posts that were made in February. Etc.
You’ll now have an XML file***** of whatever content you’ve chosen to use.
Open this XML file in any web browser of your choosing. What you’ll see will look a little bit like this image below. Notice that you only see the text and code that is behind the actual webpage. You can then save this file as a .pdf, .rtf, paste into a word .doc, and use directly in the text analysis tool of your choosing.

There is one thing to be aware of when performing a textual analysis of the body of this WordPress export. HTML tags are present in here. If you do an analysis and want to search word the word “em******” you will return a false positive every time the HTML tag for italics [literally, emphasized] is present in your document. If you want to be 100% sure, there is one more step you can take to ensure an HTML free corpus†.
on Blogger
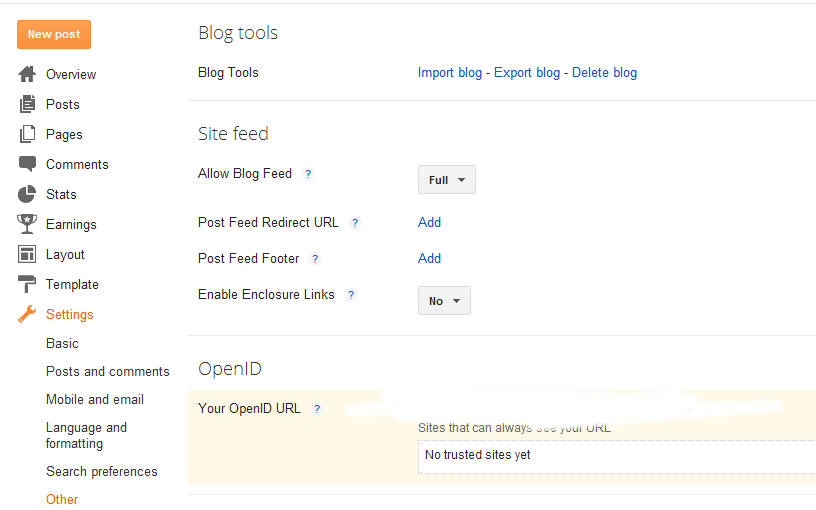
Go to your blog settings, to other, and then click on “export blog.”
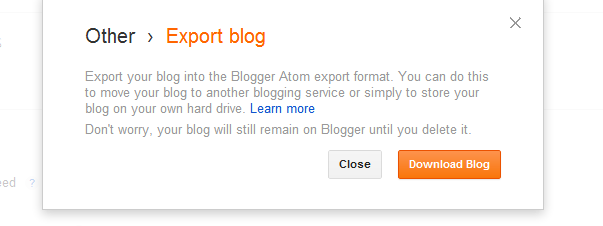
And then click “download blog.”
Once again, you will have an XML file. If This is good enough for you, feel free to being performing your Textual Analysis. If you want to hide all of the code, let’s move on to the final step- converting this to an HTML file.
† Okay. Now that you have this XML document. Highlight all of it. Copy and paste it into a Plain Text editor. [Text Edit is NOT a plain text editor!] Notepad, Notepad++, even Dreamweaver. The save that file with the extension .html. Open in your browser and all of the HTML tags have been converted back into styled text.
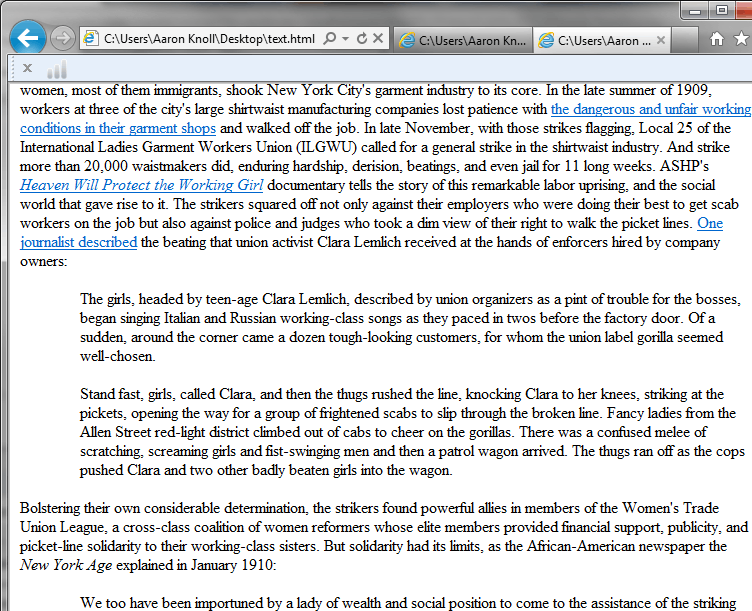
This is that same text that we looked at above in code form turned back into plain HTML
On Concluding Thoughts
The process is surely a little daunting and a bit long. But none of the steps are complex. In the most basic form, we started with a body of text that had tons of ancillary content which could adversely affect any textual analysis we wanted, and in the end we have only the text which was written by the author. As I said, I can see how this process might be overkill for a quick word analysis such as Wordle. But if the operation is more complex and going to be fed to a program such as NVivo or Atlas [among others] it is worthwhile to ensure that the tropes of how web pages are constructed do not adversely affect the research that you want to perform using the web.
The web is a great source of data, and challenges such as dealing with duplicated content are hardly unassailable. They web/blog still being a rather new medium [and even more new for being considered worthy of performing scholarly research on] and therefore we are still in the infancy of learning how to deal with the trope and design patterns. But fortunately, with RSS being a standard, and export tools coming standard on most blogging platforms these days, these obstacles are easier to overcome today than they ever have before.
If you are doing some textual analysis of a blog, best of luck and let me know how it goes.
______________________________________________________
*This is to borrow a word that I have heard often at the Graduate Center.
* The relationship between UX and UI design AND the idea of a digital dissertation is actually quite a close one. But that is a topic for a later post.
*** This is a generalization, but in this sense “significantly” refers to statistical significance only.
**** But be wary, selection bias may cast shadows on your methodology
*****It’s not true XML. This is actually a WordPress specific format which is designed specifically for moving your blog to another WordPress installation. It will work fine for our purposes, even if the presentation may be disappointing to XML fanboys and girls.
****** Not really much of a word, outside of Scrabble that is.